O wyszukiwarce
Monco PL to wyszukiwarka korpusowa, która pomaga znaleźć przykłady użycia wyrazów, fraz oraz wzorców leksykalno-gramatycznych w autentycznych próbkach współczesnej polszczyzny.
Logowanie za pomocą konta E-SCIENCE
W celu założenia konta w systemie E-SCIENCE należy przejść pod adres CLARIN SERVICES i kliknąć na przycisk LOGIN WITH E-SCIENCE

Następnie zostaniemy przekierowani do strony logowania. Na dole strony znajduje się przycisk Rejestracja, który należy kliknąć w celu założenia konta.
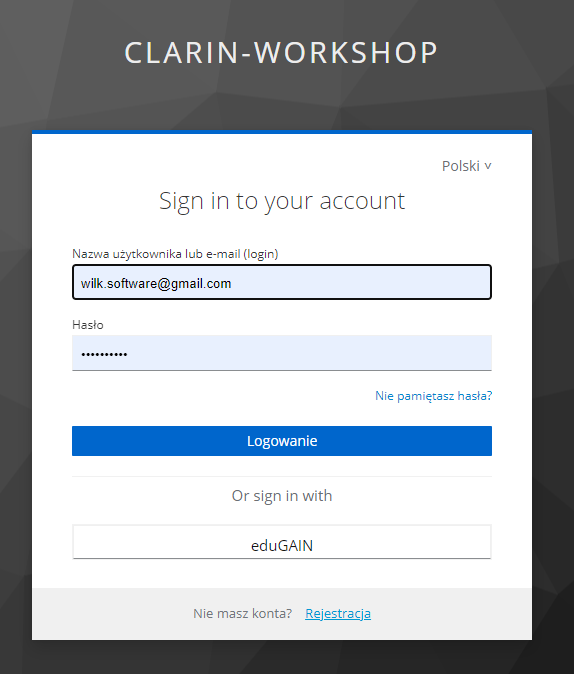
Wypełniamy formularz z danymi i potwierdzmy maila, który przyjdzie do nas na skrzynkę pocztową.
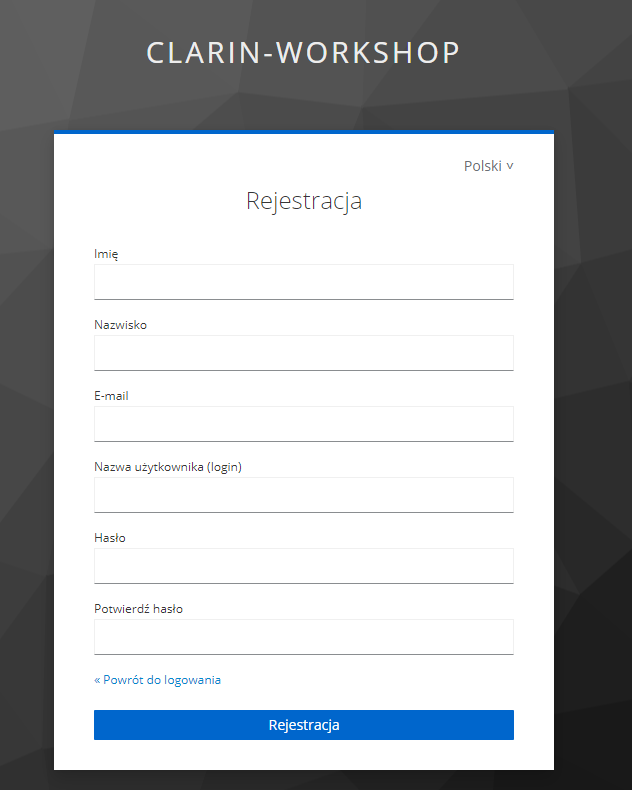
Po potwierdzeniu maila, nasze konto jest gotowe i możemy się logować w aplikacji Monco PL [Logowanie]
Indeks
Indeks wyszukiwarki zawiera obecnie ok. 8 miliardów segmentów słów i jest codziennie aktualizowany. Tak duży indeks pozwala znaleźć przykłady nawet bardzo rzadkich fraz i jednostek leksykalnych. Dodatkową zaletą stałej atkualizacji indeksu jest możliwość wyszukiwania neologizmów, neosemantyzmów i zapożyczeń, które pojawiły się w polszczyźnie w ciągu kilku ostatnich lat (zob. np. Fejs, leming, selfie).
Przeszukiwanie korpusu
Składnia zapytań korpusowych
Monco obsługuje zapytania o słowowformy, frazy, proste wzorce leksykalno-gramatyczne oraz rozszerzenia ortograficzne i morfologiczne. Na tej stronie objaśniamy najważniejsze elementy składni naszej wyszukiwarki.
Słowoformy i dokładne frazy
Aby uzyskać konkordancje dokładnych dopasowań pojedynczych słowoform lub fraz składających się z dwóch lub więcej słowoform, należy je wpisać w polu wyszukiwania i wcisnąć ikonę lupy. Wielkość liter nie ma znaczenia w zapytaniach. Prosimy nie wpisywać fraz w cudzysłowach.
Po wpisaniu zapytania:
powinniśmy otrzymać tabelę zawierającą co najmniej 20 konkordancji, np.:
Konkordancji na danej stronie może być więcej niż mógłaby to sugerować wybrana przez użytkownika wartość opcji limitu, jeżeli co najmniej jedno z pobranych z indeksu zdań zawiera więcej niż jeden kontekst pasujący do zapytania. Poza samym dopasowaniem i jego kontekstem, domyślnie wyświetlane są kolumny z nazwą źródła (portalu), z którego pochodzi cytat oraz datą publikacji tekstu. Nazwa źródła jest równocześnie bezpośrednim odnośnikiem do oryginalnej strony z pełną wersją tekstu (która może być w chwili wyświetlenia konkordancji nieaktywna). Warto pamiętać, że możliwe jest wyświetlenie kilku dodatkowych lub ukrycie aktualnie wyświetlanych kolumn z metadanymi. Aktualnie, na jednej stronie można wyświetlić do 1000 konkordancji. Przechodzenie między kolejnymi stronami wyników umożliwiają kontrolki u dołu tabeli. Wykryte w bieżących wynikach duplikaty kontekstów są przekreślane i wyszarzane, co pozwala na ich szybką identyfikację.
Poniżej podajemy przykłady zapytań o dokładne wystąpienia fraz:
Rozszerzenia morfologiczne
Niezwykle istotnym elementem składni wyszukiwarki dla korpusu polszczyzny są tzw. rozszerzenia morfologiczne, czyli możliwość wyszukania wariantów morfologicznych zadanej formy podstawowej. Dwa przykłady takich zapytań dla słów i prostych fraz przedstawiamy poniżej:
- ściemniać**
- Wielki** Brytania**
Wyniki uzyskane wskutek automatycznego rozszerzenia morfologicznego mogą nie być pełne. Nie wszystkie formy podstawowe zostały poprawnie rozpoznane w indeksie. Istnieją dwa sposoby na zwiększenie pokrycia form morfologicznych w zapytaniu. Po pierwsze, możliwe jest wymienienie wszystkich wariantów morfologicznych, które mają być uwzględnione na danej pozycji, np.:
Po drugie, możliwe jest zastosowanie rozszerzenia ortograficznego, które jednak może dać nadmiarowe wyniki, np.- ołówek|ołówk.*
Warianty
Operator wariantu | został już częściowo wprowadzony. Warto pamiętać, że można go używać również do rozszerzeń leksykalnych, np.:
Kolejność terminów zapytania
Domyślnie Monco probuje znaleźć dopasowania terminów występujących w indeksie korpusu w takiej kolejności, w jakiej zostały one zdefiniowane w zapytaniu. Aby wyłączyć ten warunek, należy rozwinąć panel opcji i odznaczyć w nim pole 'Zachowaj szyk':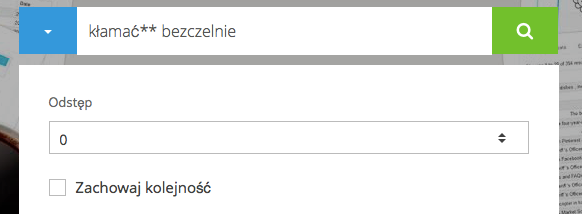 Dla zapytania:
zostaną wtedy zwrócone zarówno wystąpienia frazy 'kłamać bezczelnie' jak też jej wariantu 'bezczelnie kłamać'.
Dla zapytania:
zostaną wtedy zwrócone zarówno wystąpienia frazy 'kłamać bezczelnie' jak też jej wariantu 'bezczelnie kłamać'.
Parametr odstępu
Wyszukiwarka Monco umożliwia stosunkowo wygodne wyszukiwanie różnego rodzaju związków wyrazowych, np. idiomów, formuł konwersacyjnych, kolokacji a także nieutrwalonych kombinacji wielowyrazowych. Czasem niemożliwe jest określenie z góry dokładnego zbioru, kolejności a nawet relacji gramatycznych dla wyrazów tworzących taki związek lub frazę. Formułując zapytanie o frazy możemy zwiększyć pokrycie zwracanego zbioru wyników poprzez odpowiednie ustawienie parametru odstępu. Domyślnie jego wartość wynosi 0, co oznacza, że między kolejnym pozycjami dopasowania wyrażanymi terminami zapytania nie może wystąpić żaden wyraz.
Dla przykładu, zapytanie 'głowa** hydra**' z domyślnym ustawieniem odstępu zwróci jedynie konteksty w których te terminy zapytania występują bezpośrednio obok siebie. Wyrazy te jednak tworzą często figuratywną kolokację realizowaną w różnych konfiguracjach gramatycznych. Po zwiększeniu wartości tego parametru do 4 wśród wyników znajdą się m. in. takie dopasowania:
- hydra, która podnosi głowę
- hydra, która podnosi głowę
- hydra nie ma akurat tylu głów
- Hydrze administracji odrastają liczne głowy
Jeszcze większe pokrycie w tym przypadku można uzyskać poprzez odznaczenie opcji "Zachowaj szyk", co widać w wynikach poniższego zapytania:
Poza podanymi powyżej kontekstami widzimy tu również takie dopasowania, w których wyraz 'głowa' występuje przed wyrazem 'hydra':- głowa komunistycznej hydry
- głów biurokratycznej hydry
- głowę wymyślonej przez siebie faszystowskiej hydrze
- głowa ohydnej hydry
Znaczniki morfosyntaktyczne
Wyszukiwarka Monco umożliwia również definiowanie prostych wzorców leksykalno-gramatycznych. Kategorie morfosyntaktyczne można definiować używając specjalnej składni: <tag=XX>, gdzie XX to znacznik określający część mowy i inne kategorie gramatyczne słowa zgodnie z tagsetem NKJP. Załóżmy, że interesują nas przymiotniki występujące przez słowem 'wiara'. Poniższe zapytanie wymusza dopasowanie wystąpienia przed dowolną formą tego słowa segmentu, który został oznakowany jako przymiotnik:
Zapytanie to zwraca wyniki podobne do tych, które przedstawiono poniżej.Składnia wyszukiwarki jest kompozycyjna, co oznacza, że jej elementy można łączyć w celu zmaksymalizowania pokrycia i precyzji zapytania. Na przykład, po wyłączeniu opcji zachowania szyku wyrazów, zapytanie:
zwróci zdania zawierające kombinacje przysłówków i dowolnej formy czasownika 'ściemniać' w dowolnej kolejności tych terminów. W poniższej tabeli przedstawiamy przykłady zapytań o wyrazy, proste frazy i wzorce leksykalno-gramatyczne:| # | Zapytanie | Odstęp | Szyk | Uwagi |
|---|---|---|---|---|
| 1 | brać** jak leci | 2 | Tak | Terminy mogą występować w odległości do 2 tokenów od siebie, np. 'brali wszystko jak leci'. |
| 2 | stąpać**|chodzić**| po <tag=adj.*> <tag=subst.*> | 2 | Tak | Sekwencja stąpać + po + przym. + rzeczownik. Do 2 nieokreślonych segmentów między terminami. |
| 3 | koń** ząb** patrzeć**|zaglądać** | 4 | Nie | Różne warianty idiomu. |
| 4 | mieć** wyjebane na | 4 | Nie | Różne warianty wyrażenia idiomatycznego. |
| 5 | <tag=fin.*>|<tag=infin.*>|<tag=praet.*> przykład** | 2 | Tak | Wybrane formy czasownikowe (zob. tagset NKJP), po których występuje dowolna forma rzeczownika 'przykład'. | 6 | brzęk** <tag=.*gen.*> | 2 | Tak | Dowolna forma wyrazu 'brzęk', po której występuje dowolny wyraz w dopełniaczu. |
Sortowanie wyników
Wyszukiwarka obsługuje dwie niezależne metody sortowania wyników. Sortowanie głębokie to 'prawdziwe' sortowanie wszystkich zdań w indeksie, które pasują do zapytania po ich metadanych. Opcja 'Sortowanie konkordancji' z kolei pozwala posortować tylko zbiór wydobytych w danym żądaniu konkordancji według pasujących fragmentów zdań lub ich bezpośrednich kontekstów.
Podsumowanie wyników
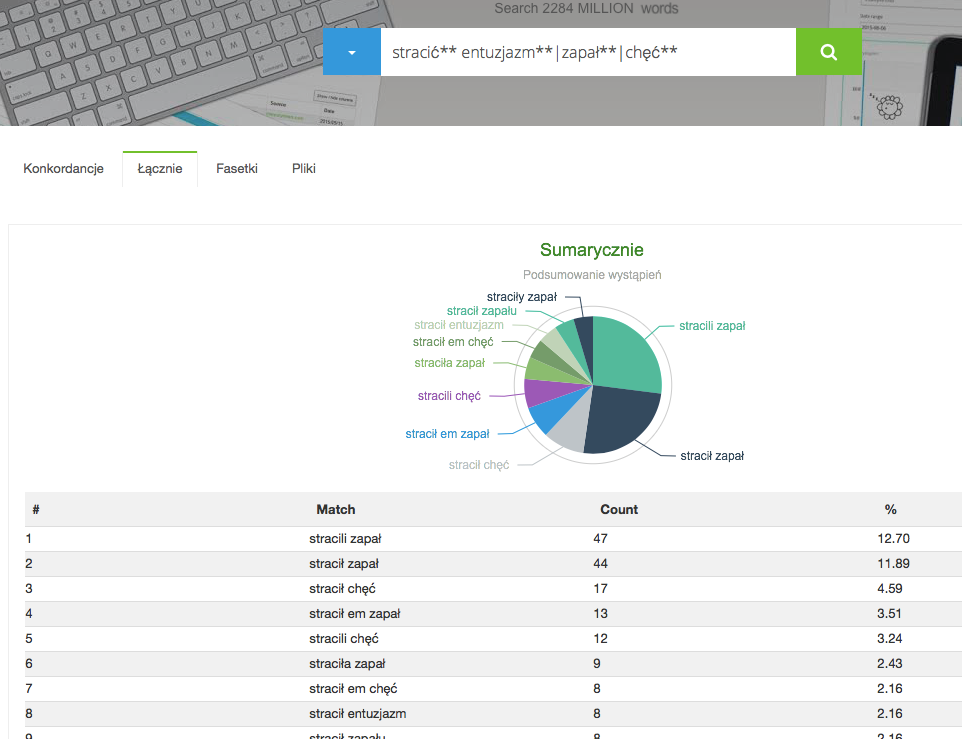
W zakładce 'Podsumowanie' tabeli wyników dostępne jest podsumowanie aktualnie wyświetlanych konkordancji (ale niekoniecznie wszystkich pasujących). Na przykład, jeżeli wykonamy następujące zapytanie i wybierzemy limit 1000 wyników:
- stracić** entuzjazm**|zapał**|chęć**
, to na podstawie pasujących konkordancji zostanie wygenerowane nastepujące podsumowanie:
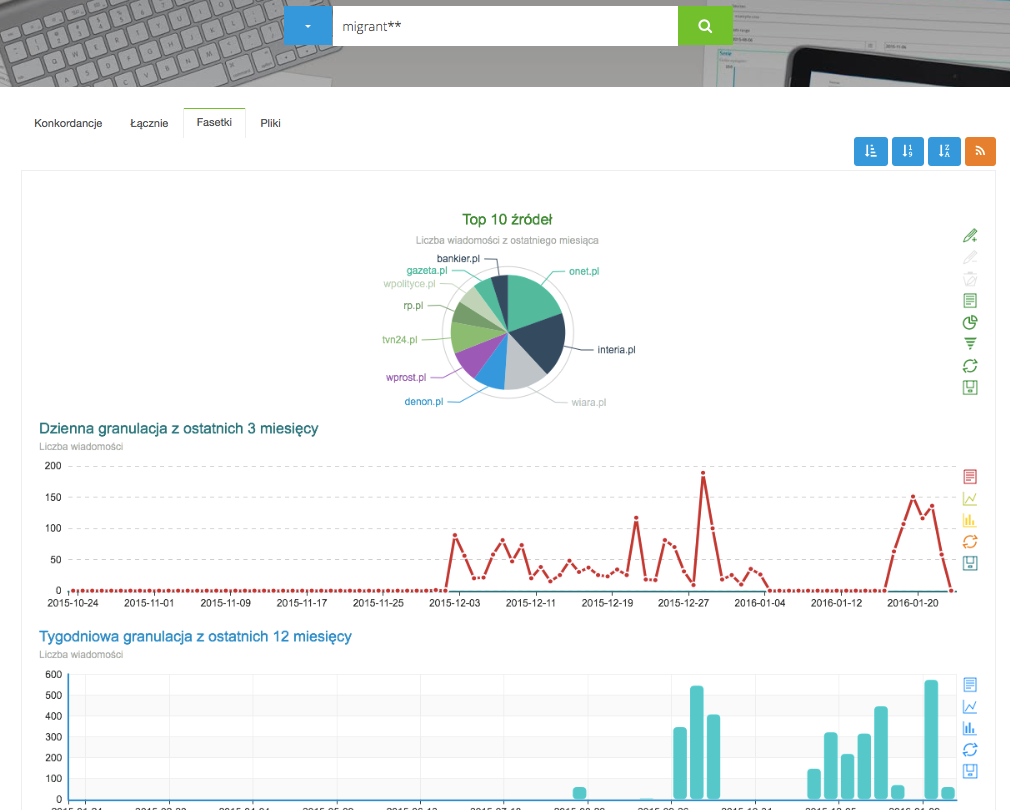
Fasety
Dla każdego zapytania korpusowego obliczane są całkowite częstości dopasowań w różnych kategoriach metadanych. Aktualnie są to źródła, w których znaleziono pasujące zdania oraz przedziały czasowe, w których wystąpiły, np.:
Eksportowanie wyników
Zalogowani użytkownicy mogą eksportować wyniki wyszukiwania w postaci arkuszy Excela.
Duplikaty
Wykryte w konkordancjach duplikaty są wyszarzane i przekreślane, co pozwala je stosunkowo łatwo zidentyfikować.
Dostęp programistyczny
Prosimy o kontakt w sprawie ewentualnego dostępu programistycznego do wyszukiwarki.